本文共 4295 字,大约阅读时间需要 14 分钟。
简介
Apache Drill is a low latency distributed query engine for large-scale datasets, including structured and semi-structured/nested data.
官网:
Apache Drill的用途:Drill是SQL查询引擎,可以构建在几乎所有的NoSQL数据库或文件系统(如:Hive, HDFS, mongo db, Amazon S3等)上,用来加速查询,比如,我们所熟知的Hive,用于在hdfs进行类SQL查询,但是利用Hive的速度比较慢,因此可以利用Drill一类的查询引擎加速查询,用于分布式大数据的实时查询等场景。
架构
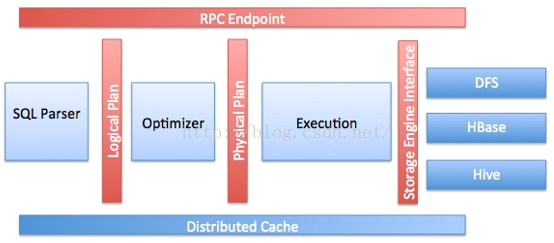
drill 通过 Storage plugin interface 即插件的形式实现在不同的数据源上构建查询引擎。
安装,分为嵌入模式与分布模式。
这里介绍linux下嵌入模式的安装:
嵌入模式无需做相关配置,较简便,首先要安装JDK 7;
进入到待安装目录,打开shell;
下载安装包,运行以下命令中其中一条:
wget http://getdrill.org/drill/download/apache-drill-1.1.0.tar.gz
或curl -o apache-drill-1.1.0.tar.gz http://getdrill.org/drill/download/apache-drill-1.1.0.tar.gz
下载文件到待安装目录后(或下载后移动至安装目录);
解压缩安装包,执行命令tar -xvzf <.tar.gz file name>
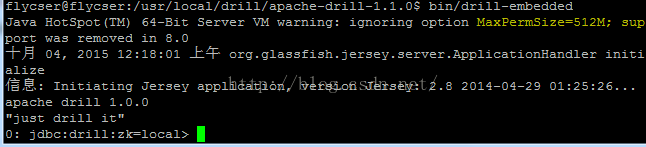
解压缩后,进入目录,此处解压过后的目录为apache-drill-1.1.0,执行命令 bin/drill,如图
此时可能会报错,显示内存不足,这里可以在子目录conf中修改drill-env.sh文件中的默认内存分配设置即可,默认是4G,对于一般家用机器,必然会报错。
即启动嵌入模式drill。
上图中最后一行表明drill已启动,可以开始执行查询,最后一行命令提示符的含义为,0表示连接数,jdbc表示连接类型,zk=local表示使用ZooKeeper本地节点。
退出命令 !quit
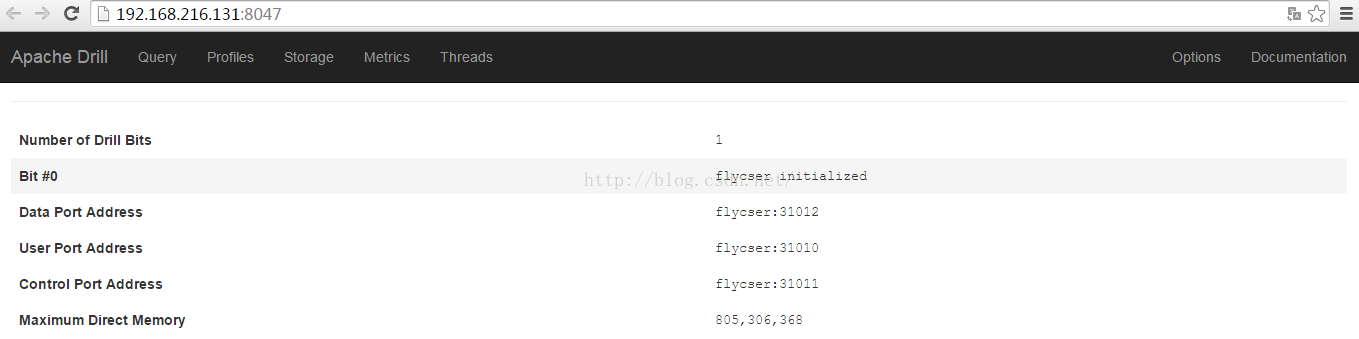
drill web访问接口,在浏览器输入 http://<IP address or host name>:8047 即可,访问效果如图:
以上我们安装好了drill工具,但是并未将其与我们的特定数据源关联,以下我们进行相关配置,使其可以对具体数据执行查询。
1. 内存配置,如上,修改,在drill-env.sh中修改参数 XX:MaxDirectMemorySize 即可。
2. 配置多用户设置
3. 配置用户权限与角色
4. 。。。待续
连接数据源
dril连接数据源,通过存储插件形式,这样增加了灵活性,对于不同的数据源,通过插件实现多数据源的兼容,drill可以连接数据库,文件,分布式文件系统,hive metastore等。
可以通过三种方式指定配置存储插件配置:
(1) 通过查询中的FROM语句
(2) 在查询语句前使用USE命令
(3) 在启动drill时指定
Web配置方式
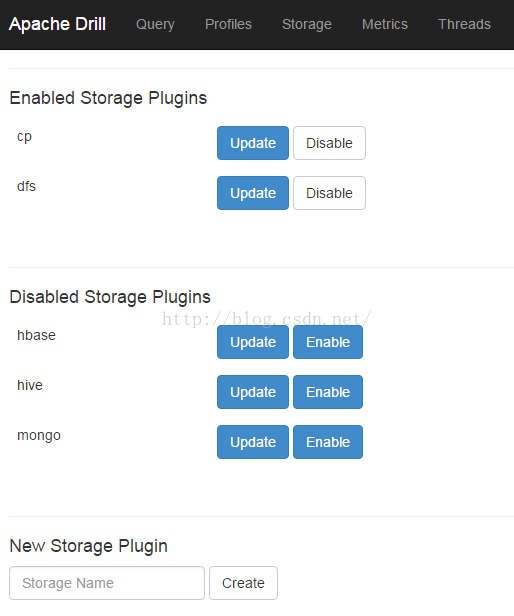
可以在 http://<IP address>:8047/storage 查看和配置存储插件,存在以下选项,
cp连接jar file
dfs连接本地文件系统或任何分布式文件系统,如hadoop,amazon s3等
hbase连接Hbase
hive连接hive metastore
mongo连接MongoDB
点击进入update选项,可以配置数据格式等选项,
可以输入存储插件名字创建新的存储插件,如图
dfs插件配置示例,如图

drill插件可配置属性介绍
| Attribute | Example Values | Required | Description |
|---|---|---|---|
| "type" | "file" "hbase" "hive" "mongo" | yes | A valid storage plugin type name. |
| "enabled" | true false | yes | State of the storage plugin. |
| "connection" | "classpath:///" "file:///" "mongodb://localhost:27017/" "hdfs://" | implementation-dependent | The type of distributed file system, such as HDFS, Amazon S3, or files in your file system, and an address/path name. |
| "workspaces" | null "logs" | no | One or more unique workspace names. If a workspace name is used more than once, only the last definition is effective. |
| "workspaces". . . "location" | "location": "/Users/johndoe/mydata" "location": "/tmp" | no | Full path to a directory on the file system. |
| "workspaces". . . "writable" | true false | no | One or more unique workspace names. If defined more than once, the last workspace name overrides the others. |
| "workspaces". . . "defaultInputFormat" | null "parquet" "csv" "json" | no | Format for reading data, regardless of extension. Default = "parquet" |
| "formats" | "psv" "csv" "tsv" "parquet" "json" "avro" "maprdb" * | yes | One or more valid file formats for reading. Drill implicitly detects formats of some files based on extension or bits of data in the file; others require configuration. |
| "formats" . . . "type" | "text" "parquet" "json" "maprdb" * | yes | Format type. You can define two formats, csv and psv, as type "Text", but having different delimiters. |
| formats . . . "extensions" | ["csv"] | format-dependent | File name extensions that Drill can read. |
| "formats" . . . "delimiter" | "\t" "," | format-dependent | Sequence of one or more characters that serve as a record separator in a delimited text file, such as CSV. Use a 4-digit hex code syntax \uXXXX for a non-printable delimiter. |
| "formats" . . . "quote" | """ | no | A single character that starts/ends a value in a delimited text file. |
| "formats" . . . "escape" | "`" | no | A single character that escapes a quotation mark inside a value. |
| "formats" . . . "comment" | "#" | no | The line decoration that starts a comment line in the delimited text file. |
| "formats" . . . "skipFirstLine" | true | no | To include or omit the header when reading a delimited text file. Set to true to avoid reading headers as data. |
也可以通过Drill Rest API进行插件配置,使用POST方式传递名字和配置两个属性,例如
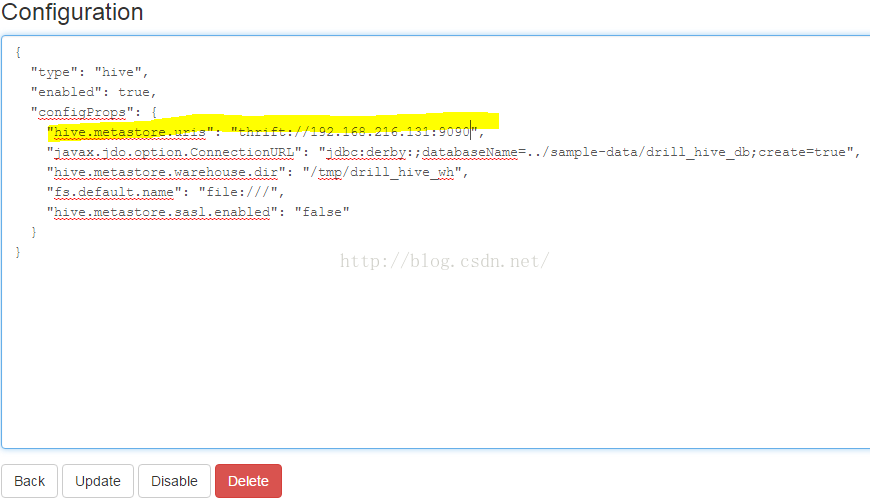
curl -X POST -/json" -d '{"name":"myplugin", "config": {"type": "file", "enabled": false, "connection": "file:///", "workspaces": { "root": { "location": "/", "writable": false, "defaultInputFormat": null}}, "formats": null}}' https://localhost:8047/storage/myplugin.json 上面命令创建一个名为myplugin的插件,用于查询本地文件系统根目录的未知文件类型。 介绍连接hive的配置,首先确保hive metastore服务启动,hive.metastore.uris: hive --service metastore
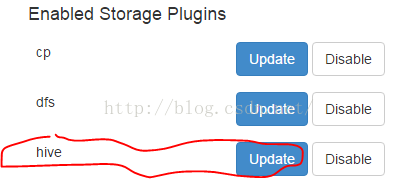
进入Drill Web接口,进入Store选项卡, http://<IP address>:8047/storage
点击hive旁的update选项,进行配置,如图
进入配置界面,在默认内容上添加如下,